Cloudbleed
Abstract
Cloudflare is a company that provides a CDN, DNS, and security services for customer’s websites. It acts as a reverse proxy, sitting between its customers’ sites and their visitors in order to add security features and improve performance. Early in 2017, a bug in Cloudflare’s server-side code was found to be leaking sensitive memory from Cloudflare’s servers into some HTML responses. This bug, similar to its namesake, the 2014 Heartbleed bug in TLS/SSL, could leak whatever data was present in memory at the time: internal headers, cookies, HTML POST bodies, and even passwords. This was exacerbated by search engines caching the leaked data- making it more public and more easily accessible. Cloudflare responded to the bug quickly and deployed a kill switch for the source of the bug (its HTML parser) within 8 hours of it being reported. Cloudflare also insists that there is no evidence suggesting the bug was exploited in the wild. However, the potential severity of the bug is difficult to overstate. Cloudflare’s reverse proxy created a single point of failure- effectively making secure encryption schemes like SSL/TLS, authentication, and other modern security efforts pointless. In this post we will be discussing Cloudbleed’s coverage in the media, the problem in Cloudflare’s HTML parser that lead to memory being leaked, and what the security community can learn from this experience going forward.
Discovery, Incentives, and Involved Parties
On February 17th, 2017, Tavis Ormandy from Google’s Project Zero security research team discovered the bug while performing tests on their fuzzing software. They randomly came across unexpected data and soon realized that they were looking at initialized memory from Cloudflare servers. After isolating the steps needed to reproduce the bug, they found a few live examples and quickly notified Cloudflare.
Project Zero is not a malicious group. They are a security research team founded by Google in 2014 in order to find zero-day vulnerabilities and report them. They have found vulnerabilities with Windows 8.1, LastPass, and other large companies. They are white hat hackers who responsibly disclose all of their findings. Their goals, as stated by Google, are to ensure that all users “be able to use the web without fear that a criminal or state-sponsored actor is exploiting software bugs to infect [their] computer.” To this end, their only task is to find vulnerabilities and report them so that they get fixed. Google has not placed any limitations and seems to have altruistic motives behind forming the team.
According to Cloudflare, there is no evidence that this bug was found by malicious attackers before Tavis Ormandy’s report on the 17th. They do not believe that this exploit was used by anyone except the Project Zero team, and so while the potential impact of this vulnerability was quite large, Cloudflare is confident that the actual harm caused was minimal.
Parties affected by the bug include Uber and other companies using Cloudflare services that had sensitive data leaked. PII was available in the clear for anyone to stumble across. Additionally, the developer behind Ragel, the HTML parser used by Cloudflare, suffered some PR issues because Cloudflare did not initially make it clear that it was their implementation, not Ragel itself, that caused the bug. Other than this, though, not much harm occurred because Google and other search engines were quick to scrub any cached PII and other sensitive data from their servers and Cloudflare believes they patched the bug before any malicious groups were aware of it.
Media Coverage
Cloudflare was able to stop the bug before any major leaks occurred. However, the media blew the dangers of the leaks out of proportion. A journalist from spamfighter even stated that “For, Cloudbleed’ name of one fresh security bug possibly hacked user-data from websites that utilize the security facility ‘Cloudflare”, claiming that the bug was a hack but it was actually a leak. Thomas Fox-Brewster from Forbes stated that ““A large company like Uber might receive somewhere between 10 billion and 50 billion requests a month and so could have leaked somewhere between 1,000 and 6,000 times,” which over exaggerate the leaks because the reported number of request can not be determined just by how many request is made by Cloudflare. The title of this article “How bad was Cloudbleed?1.2 Million Leaks Bad”, as again an over exaggeration of the useable sensitive data that was leaked.
The Bug
Cloudflare parses HTML on the fly in order to provide useful features like email obfuscation (to prevent spam) and http to https rewrites (to prefer encrypted connections for linked URLs). The memory leak bug was located inside Cloudflare’s HTML parser and essentially resulted in a classic buffer-overrun which would be triggered in specific circumstances and leak possibly sensitive data.
Triggering the Bug
The bug is triggered when an HTML page being parsed is malformed in a particular way.
<!DOCTYPE html>
<html>
<head>
<script type=
When an HTML page requested by a site visitor (and subsequently parsed by Cloudflare) contains unbalanced and unclosed script tag and attribute like the example above, the bug is triggered. On parsing this, the buffer containing the HTML is overrun and data from private server memory is included in the response sent to the requester.
The Culprit Code
Cloudflare’s HTML parser is written in Ragel, a somewhat obscure language that expresses logic by defining various state machines and ultimately generates C source code. Let’s dive into the Ragel source code that allowed the buffer overrun (luckily Cloudflare released snippets of it).
This is the Ragel code responsible for parsing a script attribute like the one above.
script_consume_attr := ((unquoted_attr_char)* :>> (space|'/'|'>'))
>{ ddctx("script consume_attr"); }
@{ fhold; fgoto script_tag_parse; }
$lerr{ dd("script consume_attr failed");
fgoto script_consume_attr; };
Here, the input HTML is matched against the regular expression ((unquoted_attr_char)* :>> (space|'/'|'>')) which represents an unspecified number of unquoted_attr_char concatenated with a space, a forward slash, or a closing bracket. If the input matches the expression, the code inside the @{} block is executed. If it does not match, the code in the $lerr{} block is executed.
Given an unbalanced script tag like the HTML example above, the $lerr{} block would be executed since the regular expression matches well-formed tags. This is where we run into trouble. In this code block we fgoto script_consume_attr which will execute this same state machine to try to parse the next attribute. The problem with this is that with HTML malformed like the one above, there is no next attribute. Instead, the parser finds raw server memory and that gets injected into the response HTML instead.
It’s also important to note the fhold in the @{} block. This keeps the parser looking at the same part of the input (rather than skipping ahead). If there were an fhold in the $lerr{} block, the memory leak would have been avoided.
The bug becomes much clearer when we look at some of the C code that this Ragel generates:
/* generated code */
if ( ++p == pe )
goto _test_eof;
Here, p is a pointer to the current character in the buffer and pe is a pointer to the character after the buffer. This is a classic buffer overrun problem in C. The == should really be >= because if p gets incremented past the value of pe the _test_eof function will not be called and instead whatever is in memory after the buffer will be referenced by p. This makes it clearer how private server memory was leaked into Cloudflare HTML responses.
What Did It Look Like?
That is how the bug works, but how did leaked data actually look in the browser? This is an example:
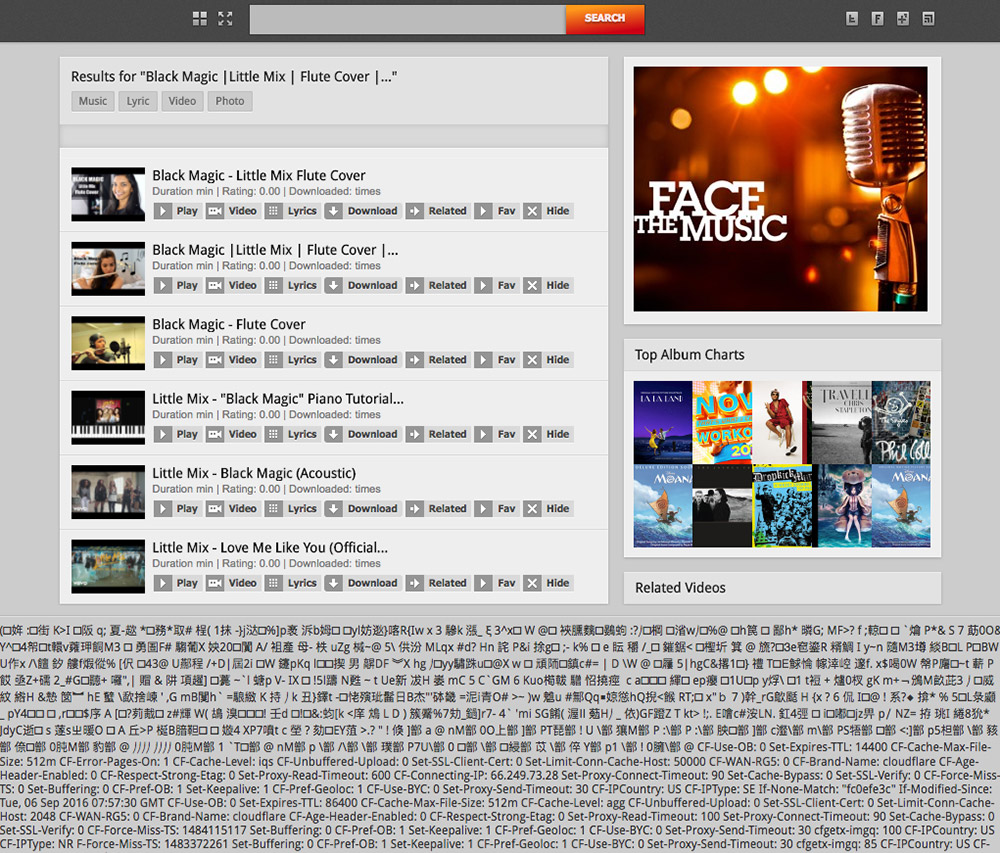
As we can see the bug directly injected data into the html file. Whatever is present in memory at the time the bug is triggered would be leaked, sometimes sensitive data, in plaintext.
Search Engine Caching
The problem was made worse by the fact that search engines had cached these pages that included leaked data. This made the leaked information more easily accessible- to find data leaked by Cloudbleed, one could simply search for Cloudflare headers and get back relevant search results.
Here is an example of Uber data that you could search for using google. You only need to search with the Cloudflare header followed by the company name.

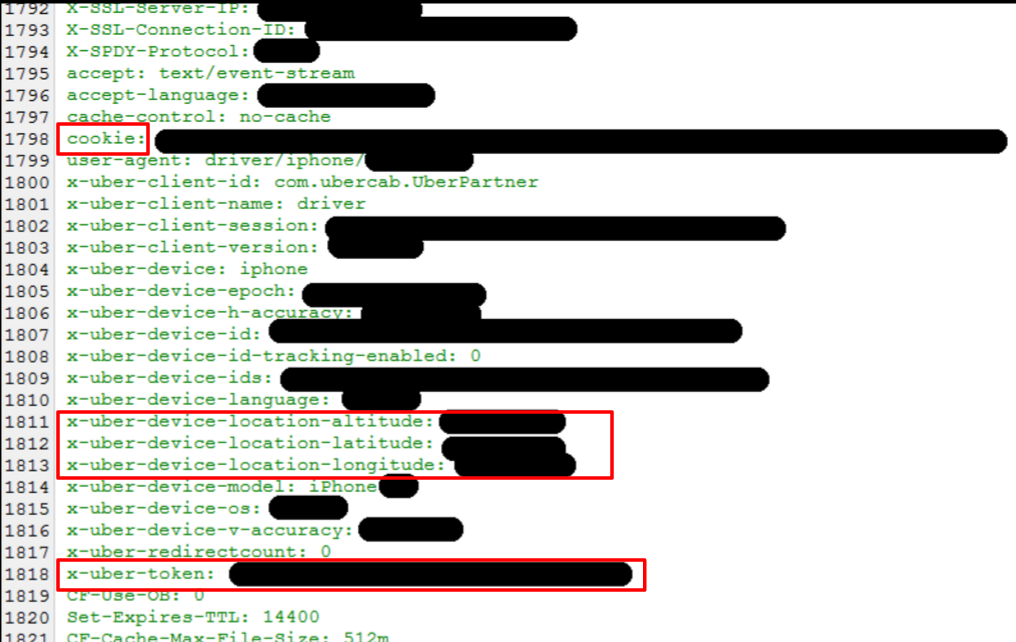
In the image above we can see the potential data leaks from Uber including a specific user’s cookie, geolocation, and an auth token. The Uber auth token and cookie are particurlary sensitive because they could potentially be used to highjack a user’s session.
The search results were quickly scrubbed by Google, Duck Duck Go and other major search engines after the initial discovery. This was done to prevent exposure of sensitive information.
Prevention and Takeaways
How could this bug and leak have been prevented? What can we learn from this ordeal?
How Could This Have Been Prevented?
-
Sand Box their servers - would prevent this since accessing a site with malformed html will only give you access of that’s site data and not other sites, making the impact minimal since a few sites using Cloudflare actually have this problem.
-
Tagged Memory - while modern web security has come a long way, there’s an argument to be made that we are ultimately putting band aids on legacy systems that weren’t designed to be secure. Companies could invest more in making underlying technologies more secure. In the case of Cloudbleed, perhaps a tagged memory architecture that restricts access to server memory more robustly could have mitigated the buffer overrun and consequently, the leak.
-
More rigorous testing of legacy code may have helped prevent Cloudbleed. The code for the HTML parser seems to have originated from Brian Pane’s open source Jitify (see the copyright info below) which we found while researching parsers written in Ragel.

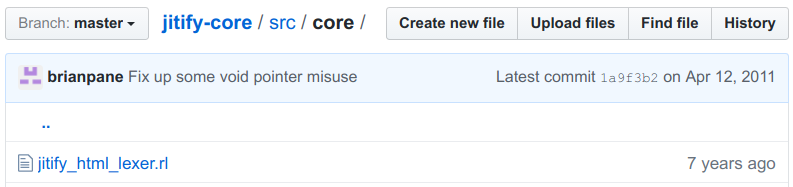 This means the code base for the parser is over 7 years old. Rigorous code review of older code may have helped prevent Cloudflare from triggering this bug while moving away from the Ragel parser to their new one.
This means the code base for the parser is over 7 years old. Rigorous code review of older code may have helped prevent Cloudflare from triggering this bug while moving away from the Ragel parser to their new one.
Cloudflare was the Single point of Failure
So what happened to all the modern security standards we learned in class and why didn’t they prevent or mitigate this bug? TLS/SSL wasn’t compromised or misused, authentication methods were behaving properly; why didn’t these help? The bug was caused by poorly written code on Cloudflare’s server itself, and this code resulted in data being leaked into HTML pages. So the pages were encrypted and authorized as usual, but contained data that wasn’t supposed to be there. This, combined with search engine caches making the data more accessible, made security frameworks in place irrelevant.
Acknowledgment
Thanks to Professor Sharon Goldberg and Ann Ming Samborski for all the feedback.
References
-
https://blog.cloudflare.com/incident-report-on-memory-leak-caused-by-cloudflare-parser-bug/
-
http://gizmodo.com/everything-you-need-to-know-about-cloudbleed-the-lates-1792710616
- http://homes.cs.washington.edu/~dcjones/biojl/parsing.html
- https://github.com/calio/ragel-cheat-sheet
- http://thingsaaronmade.com/blog/a-simple-intro-to-writing-a-lexer-with-ragel.html
- http://www.evanmiller.org/nginx-modules-guide-advanced.html#parsing
- https://bugs.chromium.org/p/project-zero/issues/detail?id=1139
- https://blog.cloudflare.com/quantifying-the-impact-of-cloudbleed/
- https://devhub.io/repos/mtourne-jitify-core
- https://techcrunch.com/2017/03/01/cloudbleed-investigation-turns-up-a-million-leaks-but-no-signs-of-exploitation/
- http://www.bankinfosecurity.com/blogs/cloudflares-cloudbleed-small-risk-but-data-still-floating-p-2407
- http://www.huffingtonpost.ca/2017/02/24/cloudbleed-bug-passwords-compromised_n_14989650.html
- https://support.cloudflare.com/hc/en-us/articles/205177068-Step-1-How-does-Cloudflare-work-
- https://blog.sqreen.io/anatomy-of-cloudflare-cloudbleed-what-you-need-to-know-and-fix/
- https://support.cloudflare.com/hc/en-us/articles/205177068-Step-1-How-does-Cloudflare-work-
- https://www.google.com/url?sa=i&rct=j&q=&esrc=s&source=images&cd=&cad=rja&uact=8&ved=0ahUKEwjJpai-2YbTAhUCKiYKHdePCcoQjhwIBQ&url=https%3A%2F%2Fblog.sqreen.io%2Fanatomy-of-cloudflare-cloudbleed-what-you-need-to-know-and-fix%2F&bvm=bv.151325232,d.amc&psig=AFQjCNHnzPmtrKeb_HVSscmayD5AkToa1Q&ust=1491254345625079
- http://www.spamfighter.com/News-20773-Security-Hack-Cloudbleed-takes-Prominence.htm
- https://xkcd.com/1353/
- https://security.googleblog.com/2014/07/announcing-project-zero.html
- https://nakedsecurity.sophos.com/2017/03/29/another-hole-opens-up-in-lastpass-that-could-take-weeks-to-fix/
- https://bugs.chromium.org/p/project-zero/issues/detail?id=118&redir=1